Не так давно мы уже писали о планируемых новых возможностях VMware vSphere 5.5, однако большинство новых функций были описаны в общих чертах, кроме того, до последнего момента так и не было окончательно известно, что же еще нового появится в vSphere 5.5. На проходящей сейчас конференции VMworld 2013 компания VMware наконец-то объявила о выходе обновленной платформы VMware vSphere 5.5, которая стала еще более мощным средством для построения виртуальных инфраструктур.
Был тут случай недавно - пишет мне товарищ, дескать, что это мы пост разместили с инфой, которая под NDA. А откуда мы должны знать, что находится под NDA, а что не под NDA? И вообще с какой стати все эти заморочки с NDA? Я вообще на тему продуктов чьих-то NDA никогда не подписывал и подписывать не собираюсь. А если появляется утечка с новыми возможностями продукта или компании - это никакой нахрен не слив инфы под NDA, а самая обычная и уже набившая оскомину реклама - радуйтесь.
Или вот приходит нам рассылка про новую версию vCloud Director, а внизу написано:
***** Confidential Information ***** Do not forward information about this program or release to anyone outside of those directly involved with beta testing. This information is highly confidential.
Information contained in this email, including version numbers, is not a commitment by VMware to provide or enhance any of the features below in any generally available product.
Или вот NVIDIA пишет:
Обращаю ваше внимание, что информация брифинга находитсяпод NDAдо 17:00 по Москве вторника, 23-го июля.
И чо? А если я им в письме напишу, что им нельзя мыться 3 месяца - они будут этот наказ соблюдать?
Так что, уважаемые вендоры, надеюсь, вам понятна позиция VM Guru с вашими NDA. Если мы их не подписывали - не пишите нам ничего на эту тему, так как эти письма отправляются прямиком в трэш по ключевому слову "NDA".
Вон у Apple тоже, конечно, утечки бывают, но в целом-то - хрен узнаешь, когда этот новый айфон выйдет. Поэтому в этом посте мы с удовольствием расскажем о новых возможностях VMware vSphere 5.5 на основе информации, взятой из сети интернет (также об этом есть на блоге Андрея и Виктора - http://vmind.ru/2013/08/15/chego-zhdat-ot-vmware-vsphere-5-5/). Естественно, не все из этих фичей могут оказаться в релизной версии, и это, само собой, не полный их список.
New OS Support
Наряду с поддержкой Windows 8.1 (ожидается в VMware View 5.5) будут поддерживаться последние релизы гостевых ОС Linux: Ubuntu, Fedora, CentOS, OpenSUSE и другие дистрибутивы.
VMware Hardware Version 10
Теперь появится новое поколение виртуального аппаратного обеспечения версии 10. Это добавит новых возможностей виртуальным машинам с точки зрения динамических сервисов виртуализации. Для редакции vSphere Enterprise Plus будет поддерживаться до 128 vCPU.
Улучшенный интерфейс, большое количество фильтров и вкладка "recent objects", позволяющая получить быстрый доступ к объектам.
Улучшения по времени отклика интерфейса и возможность управлять большим числом объектов.
vSphere Replication - теперь доступны следующие возможности по репликации виртуальных машин:
Возможность репликации виртуальных машин между кластерами для машин не с общими хранилищами (non-shared storage).
Поддержка нескольких точек для восстановления целевой реплицируемой машины. Это защищает сервисы от логических повреждений данных, изменения в которых реплицируются на резервную площадку.
Storage DRS Interoperability - возможность реплицируемых машин балансироваться по хранилищам средствами технологии Storage vMotion без прерывания репликации.
Simplified Management - улучшенная интеграция с vSphere Web Client, что позволяет мониторить процесс репликации в различных представлениях vCenter.
Поддержка технологии VSAN (см. ниже) - теперь машины на таких хранилищах поддерживаются средствами репликации.
vCenter Orchestrator - теперь это средство автоматизации существенно оптимизировано в плане масштабируемости и высокой доступности. Разработчики теперь могут использовать упрощенные функции диагностики в vCenter Orchestrator client.
Virtual SAN
О возможностях VMware Distributed Storage и vSAN мы уже писали вот в этой статье. Virtual SAN - это полностью программное решение, встроенное в серверы VMware ESXi, позволяющее агрегировать хранилища хост-серверов (SSD и HDD) в единый пул ресурсов хранения для всех хостов, что позволяет организовать ярусность хранения с необходимыми политиками для хранилищ.
Поддержка томов vVOL
Также мы писали о поддержке виртуальных томов vVOL - низкоуровневых хранилищ для каждой из виртуальных машин, с которыми будут позволены операции на уровне массива, которые сегодня доступны для традиционных LUN - например, снапшоты дискового уровня, репликация и прочее. Проще говоря, VMDK-диск машины можно будет хранить как отдельную сущность уровня хранилищ в виде vVOL, и с ней можно будет работать отдельно, без влияния на другие ВМ этого массива.
VMware Virtual Flash (vFlash)
О возможностях VMware Virtual Flash (vFlash) мы уже писали вот в этой статье. vFlash - это средство, позволяющее объединить SSD-ресурсы хост-серверов VMware ESXi в единый пул, используемый для задач кэширования, чтобы повысить быстродействие виртуальных машин. vFlash - это фреймворк, позволяющий сторонним вендорам SSD-накопителей и кэш-устройств использовать собственные алгоритмы для создания модулей обработки кэшей виртуальных машин (плагины vFlash Cache Modules). Будет реализован и собственный базовый алгоритм VMware для работы с кэшем.
Virtual Machine File System (VMFS)
Теперь VMware vSphere 5.5 поддерживает vmdk-диски объемом более 2 TБ. Теперь объем виртуального диска машины может быть размером до 64 ТБ. Несколько больших файлов теперь могут храниться в одном vmdk. Это поддерживается только для VMFS 5.
vCloud Director
Теперь продукт доступен как виртуальный модуль (Virtual Appliance) - можно использовать как встроенную так и внешнюю БД. Этот модуль по-прежнему не будет рекомендован для продакшен-среды. Рекомендуют использовать его для апробации решения.
Был существенно улучшен Content Catalog:
Улучшена производительность и стабильность синхронизации
Расширяемый протокол синхронизации
Возможность самостоятельной загрузки элементов каталога (OVF)
Кроме того, для интерфейса управления теперь поддерживается больше браузеров и ОС (в том числе поддержка Mac OS).
vCloud Networking & Security
В составе vSphere 5.5 этот продукт будет иметь следующие улучшения:
Улучшенная поддержка Link Aggregation Control Protocol (LACP) - теперь поддерживается 22 алгоритма балансировки и до 32 физических соединений в агрегированном канале.
Улучшения производительности и надежности агрегированного канала.
Кроме того, вместо vCloud Networking and Security с октября выходит новый продукт VMware NSX.
Security Features
Теперь появится распределенный сетевой экран (Distributed Firewall), являющийся одним из ключевых компонентов концепции Software Defined Datacenter. Он работает на уровне гипервизора каждого из хостов VMware ESXi, а на уровне централизованной консоли доступен мониторинг проходящих пакетов от абсолютно каждой виртуальной машины.
Политики этого сетевого экрана определяются на уровне VXLAN, поэтому нет нужды оперировать с ним на уровне IP-адресов. Ну и так как поддержка этого распределенного фаервола реализована на уровне гипервизора - то политики перемещаются вместе с виртуальной машиной, если она меняет хост средствами vMotion.
Теперь vCenter SRM будет поддерживать технологию vSAN вместе с vSphere Replication, работать с технологиями Storage DRS и Storage vMotion. Кроме того, добавлена поддержка нескольких точек восстановления реплик (Multi-Point-In-Time snapshots) при исполнении плана аварийного восстановления.
VMware vCenter Multi-Hypervisor Manager (MHM) 1.1
Об этом продукте мы уже писали вот тут. Теперь он будет поддерживать гипервизор Microsoft Hyper-V 3.0 в Windows Server 2012 R2 (а также более ранние его версии). Также появилась возможность холодной миграции ВМ с хостов Hyper-V на VMware vSphere.
Single Sign-On 2.0 (SSO)
В новой версии единого средства аутентификации продуктов VMware теперь появится улучшенная и новая поддержка следующих компонентов:
vSphere
vCenter Orchestrator
vSphere Replication
vSphere AppHA (новый продукт, который будет анонсирован на VMworld)
vCloud Director
vCloud Networking and Security (vCNS)
Технология VMware vDGA для VMware Horizon View 5.5
О технологии NVIDIA VGX мы уже писали вот тут, тут и тут. Согласно этой презентации, уже скоро мы увидим возможности шаринга и выделение GPU отдельным виртуальным машинам:
Ну что знал - рассказал. В целом, ничего революционного. Поддержку Fault Tolerance для 4-х vCPU обещают в VMware vSphere 6.0.
VMware Workstation 10 получит следующие функции (многие из этих возможностей уже были включены в майское превью, новые отмечены звездочкой):
New OS Support - появилась экспериментальная поддержка Windows 8.1, а также гостевых и хостовых ОС Ubuntu 13.04, Fedora 18 и прочих.
* VMware Hardware Version 10 - обновилось поколение виртуального аппаратного обеспечения виртуальных машин. Это дает новую функциональность создаваемых ВМ, в первую очередь, поддержку 16-ти виртуальных процессоров (vCPU) для одной машины. Для этого на вашем ПК должно быть не менее 16-ти логических процессоров (или 8 ядер с включенным HT), чем может похвастаться далеко не каждый компьютер. Также существенно была увеличена производительность, работа с подсистемой питания и улучшена поддержка новых возможностей десктопных процессоров. Кроме того, появилась поддержка виртуальных дисков объемом 8 ТБ. Появились виртуальные SATA-диски, была улучшена поддержка USB 3.0 и удвоилось число VMnet .
SSD Passthrough - ОС Windows 8 способна определить, что она работает с диска solid state drive (SSD), что позволяет ей оптимизировать работу с подсистемой ввода-вывода. В этом Technology Preview, Workstation может обнаружить, что диск ВМ размещен на SSD-носителе, и передать гостевой ОС эту информацию, чтобы та смогла включить оптимизацию.
Expiring Virtual Machines - VMware улучшила возможности Restricted Virtual Machines, которые появились в прошлых версиях. Теперь виртуальная машина может устареть в заданную дату по времени UTC. Такие машины соединяются с ресурсом VMware.com для валидации времени и предотвращения попыток пользователя снять лок с машины.
* Virtual Tablet Sensors - теперь в виртуальной машине можно получить виртуальные устройства планшетов: GPS, акселерометр, инклинометр, компас, гирометр и симуляцию окружающего света (Ambient Light). Все это пригодится при разработке программного обеспечения, например, под планшеты и телефоны на базе Windows 8.
New Converter - в этой версии VMware Converter получил несколько новых улучшений:
- Поддержка гостевых ОС Microsoft Windows 8 и Microsoft Windows Server 2012
- Поддержка гостевой ОС Red Hat Enterprise Linux 6
- Поддержка виртуальных и физических машин с дисками GUID Partition Table (GPT)
- Поддержка виртуальных и физических машин с интерфейсом Unified Extensible Firmware Interface (UEFI)
- Поддержка файловой системы EXT4
- Поддержка ВМ vSphere 5.1 (hardware version 9)
Pre-Released OVFTool - утилита командной строки VMware OVF Tool позволяет импортировать и экспортировать OVF-пакеты. Теперь она имеет улучшенные механизмы импорта шаблонов Oracle.
* VMware-KVM - очень полезный режим для тех, кто хочет скрыть от пользователя, что он работает в виртуальной машине (например, в школьных классах). В этом случае машину можно запустить командой "vmware-kvm.exe vmx-file.vmx" и она будет развернута на весь экран, комбинация клавиш Ctrl-Alt позволит выйти из машины, а кнопкой Pause/Break можно будет переключаться между консолями нескольких ВМ в полноэкранном режиме.
Windows 8 Unity Mode Support - поддержка режима бесшовной интеграции Unity теперь еще лучше интегрирована с интерфейсом Windows Metro.
Multiple Monitor Navigation - улучшенные механизмы работы с 2, 3, 4, 5 и даже 6-ю мониторами в полноэкранном режиме при переключении между экранами.
Power Off Suspended Virtual Machines - возможность выключить ВМ, поставленную "на паузу", что отменяет необходимость включать такие машины для внесения изменений в их конфигурацию.
Remote Hardware Upgrade - при удаленной работе с виртуальными машинами на платформе vSphere или другом ПК с VMware Workstation, теперь можно удаленно обновлять Hardware version.
* 30-day evaluation - теперь для активации пробной версии Workstation на 30 дней достаточно ввести email в окне установки.
Скачать VMware Workstation Technology Preview July 2013 можно по этой ссылке. Документ о новых возможностях доступен тут.
Что нового появится в VMware Workstation в этом году:
VMware Hardware Version 10 - обновилось поколение виртуального аппаратного обеспечения виртуальных машин. Это дает новую функциональность создаваемых ВМ, в первую очередь, поддержку
16-ти виртуальных процессоров (vCPU) для одной машины. Для этого на вашем ПК должно быть не менее 16-ти логических процессоров (или 8 ядер с включенным HT), чем может похвастаться далеко не каждый компьютер. Также существенно была увеличена производительность, работа с подсистемой питания и улучшена поддержка новых возможностей десктопных процессоров.
SSD Passthrough - ОС Windows 8 способна определить, что она работает с диска solid state drive (SSD), что позволяет ей оптимизировать работу с подсистемой ввода-вывода. В этом Technology Preview, Workstation может обнаружить, что диск ВМ размещен на SSD-носителе, и передать гостевой ОС эту информацию, чтобы та смогла включить оптимизацию.
Expiring Virtual Machines - VMware улучшила возможности Restricted Virtual Machines, которые появились в прошлых версиях. Теперь виртуальная машина может устареть в заданную дату по времени UTC. Такие машины соединяются с ресурсом VMware.com для валидации времени и предотвращения попыток пользователя снять лок с машины.
New Converter - в этой версии VMware Converter получил несколько новых улучшений:
- Поддержка гостевых ОС Microsoft Windows 8 и Microsoft Windows Server 2012
- Поддержка гостевой ОС Red Hat Enterprise Linux 6
- Поддержка виртуальных и физических машин с дисками GUID Partition Table (GPT)
- Поддержка виртуальных и физических машин с интерфейсом Unified Extensible Firmware Interface (UEFI)
- Поддержка файловой системы EXT4
- Поддержка ВМ vSphere 5.1 (hardware version 9)
Pre-Released OVFTool - утилита командной строки VMware OVF Tool позволяет импортировать и экспортировать OVF-пакеты.
Теперь она имеет улучшенные механизмы импорта шаблонов Oracle.
Windows 8 Unity Mode Support - поддержка режима бесшовной интеграции Unity теперь еще лучше интегрирована с интерфейсом Windows Metro.
Multiple Monitor Navigation - улучшенные механизмы работы с 2, 3, 4, 5 и даже 6-ю мониторами в полноэкранном режиме при переключении между экранами.
Power Off Suspended Virtual Machines - возможность выключить ВМ, поставленную "на паузу", что отменяет необходимость включать такие машины для внесения изменений в их конфигурацию.
Remote Hardware Upgrade - при удаленной работе с виртуальными машинами на платформе vSphere или другом ПК с VMware Workstation, теперь можно удаленно обновлять Hardware version.
Более подробная информация о новых возможностях и инструкции по установке VMware Workstation Technology Preview May 2013 приведены по этой ссылке.
Не так давно мы писали о публичной доступности программы VMware Hands-On Labs (HOL), представляющей собой онлайн-сервис, в котором пользователи могут выполнять лабораторные работы на базе различных продуктов VMware. Теперь же компания VMware объявила о запуске Hosted Beta Program, построенной на базе Hands-On Labs и предназначенной для тестирования потенциальными заказчиками VMware решений, построенных на базе продуктов vSphere, Horizon View, vCloud Director и других.
Для работы в среде Hosted Beta Program потребуется обычный браузер с поддержкой HTML5 (то есть последний Horizon View Client). Это позволит ознакомиться с новыми решениями и технологиями VMware, не тратя долгие часы на поиск оборудования и их развертывание и настройку.
Для запроса на участие Hosted Beta Program в нужно зарегистрироваться на этой странице.
Многим интересующимся технологиями виртуализации известна компания Stratus Technologies, занимающаяся вопросами непрерывной доступности виртуальных машин (Fault Tolerance). Ранее продукты этой компании были доступны на платформе Citrix XenServer, где позволяли обеспечивать непрерывную доступность программными методами (продукт everRun от купленной компании Marathon):
Теперь у компании появился программно-аппаратный комплекс Stratus ftServer systems with vSphere 5.1, интегрированный с последней версией платформы виртуализации от VMware. Возможности решения из пресс-релиза:
Обещают аптайм на уровне 99.999%, что соответствует 5.26 минут простоя в год
Один или два 8-ядерных процессора Intel с поддержкой hyper-threading и архитектуры QuickPath
Полная поддержка SMP для построения архитектуры непрерывной доступности (vSMP?)
Встроенные интерфейсы 10Gb Ethernet
Проактивная система мониторинга, предупреждающая о возможных сбоях
Система обнаружения проблем в самом сервере и операционной системе, работающая без прерывания обслуживания виртуальных машин
Минимальный overhead (<5%) на систему виртуализации
Интеграция с VMware HA
Очевидно, что Stratus суетится накануне выхода программного vSMP Fault Tolerance от самой VMware.
Кстати в пресс-релизе по ftServer говорится о полугодовой гарантии на нулевой даунтайм в $50 000, покрывающей не только серверную часть, но и гипервизор (!). Так что торопитесь - возможно, парочка серверов от Stratus достанется вам совершенно бесплатно (учитывая тот набор багов, который мы видим в vSphere 5.1).
Известный многим Duncan Epping в своем блоге рассказал об изменениях, которые произошли в механизме обнаружения события изоляции хост-сервера ESXi в VMware vSphere 5.1. Приведем их вкратце.
Как мы уже писали вот тут, кластер VMware HA следующим образом обрабатывает событие изоляции (отсутствие коммуникации с другими серверами кластера):
T+0 сек – обнаружение изоляции хоста (slave)
T+10 сек – хост slave переходит в режим выбора (“election state”)
T+25 сек – хост slave объявляет себя мастером (master)
T+25 сек – хост slave пингует адреса isolation addresses (по умолчанию один)
T+30 сек – хост slave объявляет себя изолированным и инициирует действие, указанное в isolation response
В VMware vSphere 5.1 появилось небольшое изменение, выражающееся в том, что хост ждет еще 30 секунд после объявления себя изолированным до инициации действия isolation response. Это время можно отрегулировать в следующей расширенной настройке кластера:
das.config.fdm.isolationPolicyDelaySec.
Таким образом, теперь последовательность выглядит так:
T+0 сек – обнаружение изоляции хоста (slave)
T+10 сек – хост slave переходит в режим выбора (“election state”)
T+25 сек – хост slave объявляет себя мастером (master)
T+25 сек – хост slave пингует адреса isolation addresses (по умолчанию один)
T+30 сек – хост slave объявляет себя изолированным и
T+60 сек - хост инициирует действие, указанное в isolation response
Наглядно:
Данные изменения были сделаны, чтобы обрабатывать сценарии, где не действие isolation response при наступлении изоляции хоста нужно обрабатывать через длительное время или не обрабатывать совсем.
Кроме того, не так давно были воплощены в жизнь такие полезные службы vSphere для работы с SSD-накопителями, как SSD Monitoring (реализуется демоном smartd) и Swap to SSD (использование локальных дисков для файлов подкачки виртуальных машин). Однако функции кэширования на SSD реализованы пока совсем в базовом варианте, поэтому сегодня вам будет интересно узнать о новой технологии Virtual Flash (vFlash) для SSD-накопителей в VMware vSphere, которая была анонсирована совсем недавно.
Эта технология, находящаяся в стадии Tech Preview, направлена на дальнейшую интеграцию SSD-накопителей и других flash-устройств в инфраструктуру хранения VMware vSphere. Прежде всего, vFlash - это средство, позволяющее объединить SSD-ресурсы хост-серверов VMware ESXi в единый пул, используемый для задач кэширования, чтобы повысить быстродействие виртуальных машин. vFlash - это фреймворк, позволяющий сторонним вендорам SSD-накопителей и кэш-устройств использовать собственные алгоритмы для создания модулей обработки кэшей виртуальных машин (плагины vFlash Cache Modules). Будет реализован и собственный базовый алгоритм VMware для работы с кэшем.
Основная мысль VMware - предоставить партнерам некий API для их flash-устройств, за счет которого виртуальные машины будут "умно" использовать алгоритмы кэширования. Для этого можно будет использовать 2 подхода к кэшированию: VM-aware caching и VM-transparent caching:
VM-aware Caching (vFlash Memory)
В этом режиме обработки кэширования флэш-ресурс доступен напрямую для виртуальной машины, которая может использовать его на уровне блоков. В этом случае на уровне виртуального аппаратного обеспечения у виртуальной машины есть ресурс vFlash Memory определенного объема, который она может использовать как обычный диск в гостевой ОС. То есть, приложение или операционная система должны сами думать, как этот высокопроизводительный ресурс использовать. Можно вообще использовать его не как кэш, а как обычный диск, хотя идея, конечно же, не в этом.
VM-transparent Caching (vFlash Cache)
В этом случае виртуальная машина и ее гостевая ОС не знают, что на пути команд ввода-вывода находится прослойка в виде flash-устройств, оптимизирующих производительность за счет кэширования. В этом случае задача специализированного ПО (в том числе от партнеров) - предоставить оптимальный алгоритм кэширования. В этом случае будет доступна настройка следующих параметров кэша:
Гарантированный объем (Reservation size)
Выбор программного модуля-обработчика (vFlash Cache Module)
Размер блока (настраивается в зависимости от гостевой ОС)
Что делать с кэшем при перемещении виртуальной машины посредством vMotion (перенести вместе с ней или удалить)
При vMotion сервер vCenter будет проверять наличие необходимых ресурсов кэширования для виртуальной машины на целевом хосте ESXi. Для совместимости с технологией VMware HA, виртуальная машина должна будет иметь доступные vFlash-ресурсы на хранилищах хостов в случае сбоя (соответственно, потребуется эти ресурсы гарантировать).
В целом vFlash в VMware vSphere обещает быть очень перспективной технологией, что особенно актуально на волне роста потребления SSD-накопителей, постепенно дешевеющих и входящих в повсеместное употребление.
Некоторое время назад компания VMware открыла регистрацию пользователей для приема заявок на доступ к порталу лабораторных работ VMware Hands-On Labs (HOL), которая доступна по этой ссылке (нужно указывать корпоративный email). Эти лабораторные работы (которые в большом количестве проводились на конференциях VMware VMworld) позволяют приобрести практический опыт по управлению элементами инфраструктуры VMware vSphere и другими решениями (VMware View, vCloud Director), а также получить новые технические знания на достаточно глубоком уровне - и все это онлайн, бесплатно и без необходимости покупать серверы для обучения и настраивать там соответствующие компоненты.
Недавно компания VMware объявила о том, что публичная бета-версия Hands-On Labs уже запущена, а приглашения уже начали поступать некоторым пользователям. Если вы зарегистрировались ранее, то логины и пароли должны прийти в течение последующих нескольких дней. Для новых пользователей регистрация по-прежнему доступна.
Проводимые лабораторные работы будут полезны также и для тех пользователей, кто уже применяет VMware vSphere, так как там рассматриваются различные Enterprise-компоненты платформы, такие как распределенный коммутатор vSphere Distrinuted Switch (vDS), которые могут быть не развернуты или не использоваться в производственной среде предприятия. Кроме того, лабы HOL могут оказаться полезными при подготовке к экзаменам по линии сертификации VMware Certified Professional.
Для примера название лабораторной работы: HOL-INF-02 – Explore vSphere 5.1 Distributed Switch (vDS) New Features. Полное описание лабораторных работ доступно по этой ссылке.
Таги: VMware, vSphere, Обучение, ESXi, vCenter, View, vCloud, Director
Компания Microsoft, в преддверии выпуска новой версии своего гипервизора Hyper-V 3.0 в составе ОС Windows Server 2012, предпринимает множество шагов по убеждению пользователей в том, что следует переходить на платформу Microsoft с продукта VMware vSphere.
Напомним основные мероприятия Microsoft, проделанные в последнее время:
Новая схема лицензирования Windows Server 2012, где издания Standard и Datacenter равны по функциональности, за исключением различного количества лиценцируемых виртуальных машин на хосте. В данной схеме особенно подчеркивается, что ограничения на память виртуальных машин (в отличие от vSphere) - нет.
Теперь подоспело еще одно средство, подталкивающее пользователей к миграции на платформу Hyper-V - плагин Virtual Machine Converter Plug-in for VMware vSphere Client, находящийся сейчас в бета-версии. Этот плагин позволяет администратору VMware vSphere провести миграцию виртуальной машины на vSphere через пункт контекстного меню ВМ. Поддерживаются клиенты vSphere Client 4.1 и 5.0.
Основные возможности продукта MVMC:
Миграция виртуальных машин с хостов VMware vSphere на платформу Hyper-V в составе:
Windows Server 2012 Release Candidate.
Microsoft Hyper-V Server 2012 Release Candidate
Добавление сетевых адаптеров (NICs) сконвертированным на Hyper-V машинам.
Настройка функций dynamic memory на сконвертированной машине.
Поддержка миграции ВМ, которые находятся в кластере VMware HA/DRS.
Поддержка миграции ВМ в Failover Cluster на Hyper-V.
Скачать Virtual Machine Converter Plug-in for VMware vSphere Client можно по этой ссылке.
Виктор прислал мне презентацию от того самого Ивана, который на одной из юзер-групп VMware рассматривал особенности дизайна и проектирования виртуальной инфраструктуры VMware vSphere. Часть, касающаяся виртуализации различных типов нагрузок в гостевых ОС виртуальных машин показалась мне очень интересной, поэтому я решил перевести ее и дополнить своими комментариями и ссылками. Итак, что следует учитывать при переносе и развертывании различных приложений в виртуальных машинах на платформе vSphere.
Таги: VMware, vSphere, ESXi, HA, Enterprise, VMachines
Мы уже писали о новом механизме высокой доступности VMware High Availability (HA), который появился в VMware vSphere 5 и работает на базе агентов Fault Domain Manager (FDM). Как известно, вместо primary/secondary узлов в новом HA появились роли узлов - Master (один хост кластера, отслеживает сбои и управляет восстановлением) и Slave (все остальные узлы, подчиняющиеся мастеру и выполняющие его указания в случае сбоя, а также участвующие в выборе нового мастера в случае отказа основного).
В нашей статье об HA было описано основное поведение хостов VMware ESXi и кластера HA в случае различных видов сбоев, но Iwan Rahabok сделал для этих процессов прекрасные блок-схемы, по которым понятно, как все происходит.
Если хост ESXi (Slave) не получил хартбита от Master, которые он ожидает каджую секунду, то он может либо принять участие в выборах, либо сам себя назначить мастером в случае изоляции (кликабельно):
Если хост ESXi (Master) получает heartbeat хотя бы от одного из своих Slave'ов, то он не считает себя изолированным, ну а если не получает от всех, то он изолирован и выполняет Isolation Responce в случае, если нет пинга до шлюза. Работающим в разделенном сегменте сети он себя считает, когда он может пинговать шлюз. Проверка живости хостов (Slaves) производится не только по хартбитам, но и по datastore-хартбитам (кликабельно):
Как мы уже писали в одной из статей, в VMware vSphere 5 при работе виртуальных машин с хранилищами могут возникать 2 похожих по признакам ситуации:
APD (All Paths Down) - когда хост-сервер ESXi не может получить доступа к устройству ни по одному из путей, а также устройство не дает кодов ответа на SCSI-команды. При этом хост не знает, в течение какого времени будет сохраняться такая ситуация. Типичный пример - отказ FC-коммутаторов в фабрике или выход из строя устройства хранения. В этом случае хост ESXi будет периодически пытаться обратиться к устройству (команды чтения параметров диска) через демон hostd и восстановить пути. В этом случае демон hostd будет постоянно блокироваться, что будет негативно влиять на производительность. Этот статус считается временным, так как устройство хранения или фабрика могут снова начать работать, и работа с устройством возобновится.
В логе /var/log/vmkernel.log ситуация APD выглядит подобным образом:
2011-07-30T14:47:41.187Z cpu1:2049)WARNING: NMP: nmp_IssueCommandToDevice:2954:I/O could not be issued to device "naa.60a98000572d54724a34642d71325763" due to Not found
2011-07-30T14:47:41.187Z cpu1:2049)WARNING: NMP: nmp_DeviceRetryCommand:133:Device "naa.60a98000572d54724a34642d71325763": awaiting fast path state update for failover with I/O blocked. No prior reservation exists on the device.
2011-07-30T14:47:41.187Z cpu1:2049)WARNING: NMP: nmp_DeviceStartLoop:721:NMP Device "naa.60a98000572d54724a34642d71325763" is blocked. Not starting I/O from device.
2011-07-30T14:47:41.361Z cpu1:2642)WARNING: NMP: nmpDeviceAttemptFailover:599:Retry world failover device "naa.60a98000572d54724a34642d71325763" - issuing command 0x4124007ba7c0
2011-07-30T14:47:41.361Z cpu1:2642)WARNING: NMP: nmpDeviceAttemptFailover:658:Retry world failover device "naa.60a98000572d54724a34642d71325763" - failed to issue command due to Not found (APD), try again...
2011-07-30T14:47:41.361Z cpu1:2642)WARNING: NMP: nmpDeviceAttemptFailover:708:Logical device "naa.60a98000572d54724a34642d71325763": awaiting fast path state update...
2011-07-30T14:47:42.361Z cpu0:2642)WARNING: NMP: nmpDeviceAttemptFailover:599:Retry world failover device "naa.60a98000572d54724a34642d71325763" - issuing command 0x4124007ba7c0
2011-07-30T14:47:42.361Z cpu0:2642)WARNING: NMP: nmpDeviceAttemptFailover:658:Retry world failover device "naa.60a98000572d54724a34642d71325763" - failed to issue command due to Not found (APD), try again...
2011-07-30T14:47:42.361Z cpu0:2642)WARNING: NMP: nmpDeviceAttemptFailover:708:Logical device "naa.60a98000572d54724a34642d71325763": awaiting fast path state update...
Ключевые слова здесь: retry, awaiting. Когда вы перезапустите management agents, то получите такую вот ошибку:
Not all VMFS volumes were updated; the error encountered was 'No connection'.
Errors:
Rescan complete, however some dead paths were not removed because they were in use by the system. Please use the 'storage core device world list' command to see the VMkernel worlds still using these paths.
Error while scanning interfaces, unable to continue. Error was Not all VMFS volumes were updated; the error encountered was 'No connection'.
В этом случае надо искать проблему в фабрике SAN или на массиве.
PDL (Permanent Device Loss) - когда хост-серверу ESXi удается понять, что устройство не только недоступно по всем имеющимся путям, но и удалено совсем, либо сломалось. Определяется это, в частности, по коду ответа для SCSI-команд, например, вот такому: 5h / ASC=25h / ASCQ=0 (ILLEGAL REQUEST / LOGICAL UNIT NOT SUPPORTED) - то есть такого устройства на массиве больше нет (понятно, что в случае APD по причине свича мы такого ответа не получим). Этот статус считается постоянным, так как массив ответил, что устройства больше нет.
А вообще есть вот такая табличка для SCSI sense codes, которые вызывают PDL:
В случае статуса PDL гипервизор в ответ на запрос I/O от виртуальной машины выдает ответ VMK_PERM_DEV_LOSS и не блокирует демон hostd, что, соответственно, не влияет на производительность. Отметим, что как в случае APD, так и в случае PDL, виртуальная машина не знает, что там произошло с хранилищем, и продолжает пытаться выполнять команды ввода-вывода.
Такое разделение статусов в vSphere 5 позволило решить множество проблем, например, в случае PDL хост-серверу больше не нужно постоянно пытаться восстановить пути, а пользователь может удалить сломавшееся устройство с помощью операций detach и unmount в интерфейсе vSphere Client (в случае так называемого "Unplanned PDL"):
В логе /var/log/vmkernel.log ситуация PDL (в случае Unplanned PDL) выглядит подобным образом:
2011-08-09T10:43:26.857Z cpu2:853571)VMW_SATP_ALUA: satp_alua_issueCommandOnPath:661: Path "vmhba3:C0:T0:L0" (PERM LOSS) command 0xa3 failed with status Device is permanently unavailable. H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0.
2011-08-09T10:43:26.857Z cpu2:853571)VMW_SATP_ALUA: satp_alua_issueCommandOnPath:661: Path "vmhba4:C0:T0:L0" (PERM LOSS) command 0xa3 failed with status Device is permanently unavailable. H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0.
2011-08-09T10:43:26.857Z cpu2:853571)WARNING: vmw_psp_rr: psp_rrSelectPathToActivate:972:Could not select path for device "naa.60a98000572d54724a34642d71325763".
2011-08-09T10:43:26.857Z cpu2:853571)WARNING: ScsiDevice: 1223: Device :naa.60a98000572d54724a34642d71325763 has been removed or is permanently inaccessible.
2011-08-09T10:43:26.857Z cpu3:2132)ScsiDeviceIO: 2288: Cmd(0x4124403c1fc0) 0x9e, CmdSN 0xec86 to dev "naa.60a98000572d54724a34642d71325763" failed H:0x8 D:0x0 P:0x0
2011-08-09T10:43:26.858Z cpu3:2132)WARNING: NMP: nmp_DeviceStartLoop:721:NMP Device "naa.60a98000572d54724a34642d71325763" is blocked. Not starting I/O from device.
2011-08-09T10:43:26.858Z cpu2:2127)ScsiDeviceIO: 2316: Cmd(0x4124403c1fc0) 0x25, CmdSN 0xecab to dev "naa.60a98000572d54724a34642d71325763" failed H:0x1 D:0x0 P:0x0 Possible sense data: 0x5 0x25 0x0.
2011-08-09T10:43:26.858Z cpu2:854568)WARNING: ScsiDeviceIO: 7330: READ CAPACITY on device "naa.60a98000572d54724a34642d71325763" from Plugin "NMP" failed. I/O error
2011-08-09T10:43:26.858Z cpu2:854568)ScsiDevice: 1238: Permanently inaccessible device :naa.60a98000572d54724a34642d71325763 has no more open connections. It is now safe to unmount datastores (if any) and delete the device.
2011-08-09T10:43:26.859Z cpu3:854577)WARNING: NMP: nmpDeviceAttemptFailover:562:Retry world restore device "naa.60a98000572d54724a34642d71325763" - no more commands to retry
Ключевое слово здесь - permanently.
Становится понятно, что в случае, когда устройство хранения (LUN) реально сломалось или удалено сознательно, лучше всего избежать ситуации APD и попасть в статус PDL. Сделать это удается хост-серверу ESXi не всегда - по прежнему в vSphere 5.0 Update 1 это обрабатывается в ограниченном количестве случаев, но в vSphere 5.1 обещают существенно доработать этот механизм.
Также есть Advanced Settings на хосте ESXi, которые позволяют управлять дальнейшей судьбой машины, которая оказалась жертвой ситуации PDL. В частности есть 2 следующие расширенные настройки (начиная с vSphere 5.0 Update 1) - первая в категории "Disk", а вторая в расширенных настройках кластера HA:
disk.terminateVMonPDLDefault - если эта настройка включена (True), то в ситуации PDL для устройства, где находится ВМ, эта машина будет выключена. Настройка задается на уровне хоста ESXi и требует его перезагрузки для ее применения.
das.maskCleanShutdownEnabled - это настройка, будучи включенной (True), позволяет механизму VMware HA приступить к восстановлению виртуальной машины. Соответственно, если она выключена, то HA проигнорирует выключение виртуальной машины в случае ее "убийства" при включенной первой настройке.
Рекомендуется, чтобы обе эти настройки были включены.
Все описанные выше механизмы могут очень пригодиться при построении и обработке сбоев в "растянутых кластерах" VMware HA, построенных между географически разнесенными датацентрами. Об этом всем детально написано в документе "VMware vSphere Metro Storage Cluster Case Study".
Таги: VMware, vSphere, Storage, Performance, Troubleshooting, HA, ESXi
Мы уже некоторое время назад писали про различные особенности томов VMFS, где вскользь касалисьпроблемы блокировок в этой кластерной файловой системе. Как известно, в платформе VMware vSphere 5 реализована файловая система VMFS 5, которая от версии к версии приобретает новые возможности.
При этом в VMFS есть несколько видов блокировок, которые мы рассмотрим ниже. Блокировки на томах VMFS можно условно разделить на 2 типа:
Блокировки файлов виртуальных машин
Блокировки тома
Блокировки файлов виртуальных машин
Эти блокировки необходимы для того, чтобы файлами виртуальной машины мог в эксклюзивном режиме пользоваться только один хост VMware ESXi, который их исполняет, а остальные хосты могли запускать их только тогда, когда этот хост вышел из строя. Назвается этот механизм Distributed Lock Handling.
Блокировки важны, во-первых, чтобы одну виртуальную машину нельзя было запустить одновременно с двух хостов, а, во-вторых, для их обработки механизмом VMware HA при отказе хоста. Для этого на томе VMFS существует так называемый Heartbeat-регион, который хранит в себе информацию о полученных хостами блокировок для файлов виртуальных машин.
Обработка лока на файлы ВМ происходит следующим образом:
Хосты VMware ESXi монтируют к себе том VMFS.
Хосты помещают свои ID в специальный heartbeat-регион на томе VMFS.
ESXi-хост А создает VMFS lock в heartbeat-регионе тома для виртуального диска VMDK, о чем делается соответствующая запись для соответствующего ID ESXi.
Временная метка лока (timestamp) обновляется этим хостом каждые 3 секунды.
Если какой-нибудь другой хост ESXi хочет обратиться к VMDK-диску, он проверяет наличие блокировки для него в heartbeat-регионе. Если в течение 15 секунд (~5 проверок) ESXi-хост А не обновил timestamp - хосты считают, что хост А более недоступен и блокировка считается неактуальной. Если же блокировка еще актуальна - другие хосты снимать ее не будут.
Если произошел сбой ESXi-хоста А, механизм VMware HA решает, какой хост будет восстанавливать данную виртуальную машину, и выбирает хост Б.
Далее все остальные хосты ESXi виртуальной инфраструктуры ждут, пока хост Б снимет старую и поставит свою новую блокировку, а также накатит журнал VMFS.
Данный тип блокировок почти не влияет на производительность хранилища, так как происходят они в нормально функционирующей виртуальной среде достаточно редко. Однако сам процесс создания блокировки на файл виртуальной машины вызывает второй тип блокировки - лок тома VMFS.
Блокировки на уровне тома VMFS
Этот тип блокировок необходим для того, чтобы хост-серверы ESXi имели возможность вносить изменения в метаданные тома VMFS, обновление которых наступает в следующих случаях:
Создание, расширение (например, "тонкий" диск) или блокировка файла виртуальной машины
Изменение атрибутов файла на томе VMFS
Включение и выключение виртуальной машины
Создание, расширение или удаление тома VMFS
Создание шаблона виртуальной машины
Развертывание ВМ из шаблона
Миграция виртуальной машины средствами vMotion
Для реализации блокировок на уровне тома есть также 2 механизма:
Механизм SCSI reservations - когда хост блокирует LUN, резервируя его для себя целиком, для создания себе эксклюзивной возможности внесения изменений в метаданные тома.
Механизм "Hardware Assisted Locking", который блокирует только определенные блоки на устройстве (на уровне секторов устройства).
Наглядно механизм блокировок средствами SCSI reservations можно представить так:
Эта картинка может ввести в заблуждение представленной последовательностью операций. На самом деле, все происходит не совсем так. Том, залоченный ESXi-хостом А, оказывается недоступным другим хостам только на период создания SCSI reservation. После того, как этот reservation создан и лок получен, происходит обновление метаданных тома (более длительная операция по сравнению с самим резервированием) - но в это время SCSI reservation уже очищен, так как лок хостом А уже получен. Поэтому в процессе самого обновления метаданных хостом А все остальные хосты продолжают операции ввода-вывода, не связанные с блокировками.
Надо сказать, что компания VMware с выпуском каждой новой версии платформы vSphere вносит улучшения в механизм блокировки, о чем мы уже писали тут. Например, функция Optimistic Locking, появившаяся еще для ESX 3.5, позволяет собирать блокировки в пачки, максимально откладывая их применение, а потом создавать один SCSI reservation для целого набора локов, чтобы внести измененения в метаданные тома VMFS.
С появлением версии файловой системы VMFS 3.46 в vSphere 4.1 появилась поддержка функций VAAI, реализуемых производителями дисковых массивов, так называемый Hardware Assisted Locking. В частности, один из алгоритмов VAAI, отвечающий за блокировки, называется VAAI ATS (Atomic Test & Set). Он заменяет собой традиционный механизм SCSI reservations, позволяя блокировать только те блоки метаданных на уровне секторов устройства, изменение которых в эксклюзивном режиме требуется хостом. Действует он для всех перечисленных выше операций (лок на файлы ВМ, vMotion и т.п.).
Если дисковый массив поддерживает ATS, то традиционная последовательность SCSI-комманд RESERVE, READ, WRITE, RELEASE заменяется на SCSI-запрос read-modify-write для нужных блокировке блоков области метаданных, что не вызывает "замораживания" LUN для остальных хостов. Но одновременно метаданные тома VMFS, естественно, может обновлять только один хост. Все это лучшим образом влияет на производительность операций ввода-вывода и уменьшает количество конфликтов SCSI reservations, возникающих в традиционной модели.
По умолчанию VMFS 5 использует модель блокировок ATS для устройств, которые поддерживают этот механизм VAAI. Но бывает такое, что по какой-либо причине, устройство перестало поддерживать VAAI (например, вы откатили обновление прошивки). В этом случае обработку блокировок средствами ATS для устройства нужно отменить. Делается это с помощью утилиты vmkfstools:
vmkfstools --configATSOnly 0 device
где device - это пусть к устройству VMFS вроде следующего:
Все разработчики, но не все администраторы VMware vSphere 5 знают, что есть такой инструмент Managed Object Browser (MOB), который позволяет просматривать структуру программных объектов хоста или сервера vCenter и вызывать различные методы через API.
Работать с MOB через браузер можно двумя способами (потребуется ввод административного пароля):
По ссылке на хост ESXi: http://<имя хоста>/mob
По ссылке на сервер vCenter: http://<имя vCenter>/mob
Вот, например, методы для работы с виртуальными дисками:
Вообще, полазить там для администратора будет интересно и полезно - можно узнать много нового о том, какие свойства есть у различных объектов vSphere. И прямо оттуда можно создавать различные объекты виртуальной среды с их параметрами.
Ну а пост этот о том, что в VMware vSphere 5 появился еще один раздел MOB - mobfdm, доступный по ссылке:
http://<имя хоста>/mobfdm
Этот MOB позволяет вызывать методы Fault Domain Manager, отвечающего за работу механизма VMware HA. Там можно узнать много интересного: какие хосты master и slave, список защищенных ВМ, Heartbeat-датасторы, состояние кластера и многое другое.
Покопайтесь - это интересно.
Таги: VMware, vSphere, Обучение, ESXi, vCenter, VMachines, FDM, HA
В последнее время все больше пользователей виртуализуют критичные базы данных под управлением СУБД Oracle в виртуальных машинах VMware vSphere. При этом есть миф о том, что Oracle не поддерживает свои СУБД в виртуальных машинах, и, если что-то случится, то получить техническую поддержку будет невозможно. Это не так.
Техническая поддержка Oracle для ВМ на VMware vSphere
На самом деле у Oracle есть документ "MyOracleSupport Document ID #249212" в котором прописаны принципы работы с техподдержкой при работе СУБД в ВМ VMware vSphere:
Вкратце их можно изложить так:
1. Действительно, Oracle не сертифицирует работу своих СУБД в виртуальных машинах VMware.
2. Если у вас возникает проблема с БД Oracle в виртуальной машине VMware, то Oracle смотрит, есть ли подобная проблема для физической системы, либо вы можете продемонстрировать, что проблема повторяется на физической машине, а не только в ВМ. Если проблема относится именно к виртуальной машине и не проявляется на физической системе, либо решение от техподдержки Oracle работает только для физического сервера - вас направляют к техподдержке VMware. Однако отметим, что VMware заявляет, что подобных проблем в ее практике еще не было.
Теперь, что касается самой VMware - у них есть отдельная политика технической поддержки "Oracle Support Policy". В ней, в частности, написано, что VMware принимает запросы на техподдержку касательно ВМ Oracle, работающих на vSphere, после чего взаимодействует со службой техподдержки Oracle через TSANet для поиска причины проблемы и решения. Тут важно, что за такие кейсы отвечает сама VMware.
1. Виртуальные машины с СУБД Oracle могут работать на хостах VMware ESX/ESXi, у которых либо все физические процессоры (ядра), либо их часть лицензированы под Oracle. Оптимально, конечно, лицензировать весь хост, однако если это дорого, можно лицензировать и несколько процессоров, после чего привязать конкретные виртуальные машины к физическим процессорам хоста, используя vSphere Client:
Либо используя vSphere Web Client:
Однако, как вы можете прочитать в документе от VMware (см. комментарии к заметке), компания Oracle не признает такого разделения лицензий по процессорам на хосте, хотя сама VMware этим очень недовольна. Поэтому вам придется лицензировать все процессоры хоста, при этом вы там сможете запустить столько экземпляров Oracle, сколько потребуется.
Возможно, эта ситуация в будущем изменится, и можно будет лицензировать отдельные процессоры хоста.
2. Если вы хотите, чтобы виртуальная машина с Oracle перемещалась на другой хост, то все процессоры исходного и целевого хостов должны быть лицензированы Oracle.
3. Что касается кластеров VMware HA/DRS, то тут нужно быть внимательным. Оптимальное решение - это создать отдельный кластер для ВМ с Oracle и лицензировать все процессоры всех хостов в нем, если у вас достаточно виртуальных машин, нагрузки и денег для такой задачи. Если недостаточно - можно лицензировать часть хостов (но, опять-таки, целиком), после чего выставить для них DRS Host Affinity Rules таким образом, чтобы виртуальные машины с Oracle всегда оставались на лицензированных хостах:
Для получения более полной информации о лицензировании Oracle в виртуальной среде VMware vSphere читайте приведенный выше документ.
В данной статье объединены все общедоступные на сегодняшний день расширенные настройки кластера VMware HA (с учетом нововведений механизма) для обеспечения высокой доступности сервисов в виртуальных машинах VMware vSphere 5.0 и более ранних версий. Отказоустойчивость достигается двумя способами: средствами VMware HA на уровне хостов ESXi (на случай отказов оборудования или гипервизора) и средствами VMware VM Monitoring (зависание гостевой операционной системы).
На каждом хосте службой VMware HA устанавливается агент Fault Domain Manager (FDM), который пришел на смену агентам Legato AAM (Automated Availability Manager). В процессе настройки кластера HA один из агентов выбирается как Master, все остальные выполняют роль Slaves (мастер координирует операции по восстановлению, а в случае его отказа выбирается новый мастер). Теперь больше нет primary/secondary узлов. Одно из существенных изменений VMware HA - это Datastore Heartbeating, механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами.
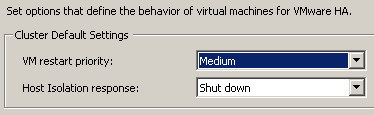
Задать Advanced Options для VMware HA (иногда их называют Advanced Settings) можно, нажав правой кнопкой на кластер в vSphere Client и далее выбрав пункт "Edit Settings", где уже нужно вводить их как указано на картинке:
Список Advanced Options для VMware HA, действующих только в vSphere 5.0:
das.ignoreinsufficienthbdatastore - определяет, будет ли игнорировано сообщение о количестве имеющихся Heartbeat-хранилищ, которое меньше сконфигурированного в настройке das.heartbeatdsperhost (по умолчанию - это 2 хранилища). То есть если Heartbeat-хранилище присутствует только одно - будет выведено следующее сообщение:
Выставление значения этого параметра в true уберет это предупреждение из vSphere Client.
das.heartbeatdsperhost - определяет количество Heartbeat-хранилищ, которое можно регулировать данной настройкой (допустимые значения - от 2 до 5). По умолчанию, данное значение равно 2.
das.config.log.maxFileNum - определяет количество лог-файлов, в пределах которого будет происходить их ротация.
das.config.log.maxFileSize - максимальный размер лог-файла, задаваемый в байтах.
das.config.log.directory - путь для хранения лог-файлов VMware HA. При задании настроек логов следует руководствоваться следующей таблицей (подробнее читайте тут на последних страницах):
das.config.fdm.deadIcmpPingInterval - интервал между пингами по протоколу ICMP для определения доступности Slave-хоста ESXi в сети со стороны Master, в случае, если нет коммуникации с FDM-агентом Slave-хоста (используется, чтобы определить - сломался агент FDM или хост вышел из строя). По умолчанию задано значение 10 (секунд).
das.config.fdm.icmpPingTimeout - таймаут, который хост (мастер) ожидает перед получением ответа на пинг, при неполучении которого он считает один из хостов недоступным из сети (то есть время, которое он дает для ответа на пинг, после чего начинаются операции по восстановлению ВМ). По умолчанию задано значение 5 (секунд).
das.config.fdm.hostTimeout - таймаут, который мастер ожидает после события неполученного хартбита от FDM-агента хоста после чего он определяет является ли хост отказавшим (dead), изолированным (isolated) или в другом сегменте разделенной сети (partitioned). По умолчанию задано значение 10 (секунд). Сами же хартбиты между мастером и slave-хостами посылаются каждую секунду.
das.config.fdm.stateLogInterval - частота записи состояния кластера в лог-файл. По умолчанию выставлено в 600 (секунд).
das.config.fdm.ft.cleanupTimeout - когда сервер vCenter инициирует запуск Secondary-машины, защищенной с помощью Fault Tolerance, он информирует мастера HA о том, что он начал этот процесс. Далее мастер ждет время, выставленное в этой настройке, и определяет запустилась ли эта виртуальная машина. Если не запустилась - то он самостоятельно инициирует ее повторный запуск. Такая ситуация может произойти, когда во время настройки FT вдруг вышел из строя сервер vCenter. По умолчанию задано значение 900 (секунд).
das.config.fdm.storageVmotionCleanupTimeout - когда механизм Storage vMotion перемещает виртуальную машину с/на хосты ESX 4.1 или более ранней версии, может возникнуть конфликт, когда HA считает, что это не хранилище ВМ переместилось, а сама ВМ отказала. Поэтому данная настройка определяет, сколько времени мастеру нужно подождать, чтобы завершилась операция Storage vMotion, перед принятием решения о перезапуске ВМ. См. также нашу заметку тут. По умолчанию задано значение 900 (секунд).
das.config.fdm.policy.unknownStateMonitorPeriod - определяет сколько агент мастера ждет отклика от виртуальной машины, перед тем как посчитать ее отказавшей и инициировать процедуру ее перезапуска.
das.config.fdm.event.maxMasterEvents - определяет количество событий, которые хранит мастер операций HA.
das.config.fdm.event.maxSlaveEvents - определяет количество событий, которые хранят Slave-хосты HA.
Список Advanced Options для VMware HA в vSphere 5.0 и более ранних версиях:
das.defaultfailoverhost- сервер VMware ESXi (задается короткое имя), который будет использоваться в первую очередь для запуска виртуальных машин в случае сбоя других ESXi. Если его емкости недостаточно для запуска всех машин – VMware HA будет использовать другие хосты.
das.isolationaddress[n] - IP-адрес, который используется для определения события изоляции хостов. По умолчанию, это шлюз (Default Gateway) сервисной консоли. Этот хост должен быть постоянно доступен. Если указано значение n, например, das.isolationaddress2, то адрес также используется на проверку события изоляции. Можно указать до десяти таких адресов (диапазон n от 1 до 10).
das.failuredetectioninterval - значение в миллисекундах, которое отражает время, через которое хосты VMware ESX Server обмениваются хартбитами. По умолчанию равно 1000 (1 секунда).
das.usedefaultisolationaddress - значение-флаг (true или false, по умолчанию - true), которое говорит о том, использовать ли Default Gateway как isolation address (хост, по которому определяется событие изоляции). Параметр необходимо выставить в значение false, если вы планируете использовать несколько isolation-адресов от das.isolationaddress1 до das.isolationaddress10, чтобы исключить шлюз из хостов, по которым определяется событие изоляции.
das.powerOffonIsolation - значение флаг (true или false), используемое для перекрытия настройки isolation response. Если установлено как true, то действие «Power Off» - активно, если как false - активно действие «Leave powered On». Неизвестно, работает ли в vSphere 5.0, но в более ранних версиях работало.
das.vmMemoryMinMB - значение в мегабайтах, используемое для механизма admission control для определения размера слота. При увеличении данного значения VMware HA резервирует больше памяти на хостах ESX на случай сбоя. По умолчанию, значение равно 256 МБ.
das.vmCpuMinMHz - значение в мегагерцах, используемое для механизма admission control для определения размера слота. При увеличении данного значения VMware HA резервирует больше ресурсов процессора на хостах ESX на случай сбоя. По умолчанию, значение равно 256 МГц (vSphere 4.1) и 32 МГц (vSphere 5).
das.conservativeCpuSlot - значение-флаг (true или false), определяющее как VMware HA будет рассчитывать размер слота, влияющего на admission control. По умолчанию установлен параметр false, позволяющий менее жестко подходить к расчетам. Если установлено в значение true – механизм будет работать как в VirtualCenter 2.5.0 и VirtualCenter 2.5.0 Update 1. Неизвестно, осталась ли эта настройка актуальной для vSphere 5.0.
das.allowVmotionNetworks - значение-флаг, позволяющее или не позволяющее использовать физический адаптер, по которому идет трафик VMotion (VMkernel + VMotion Enabled), для прохождения хартбитов.Используется только для VMware ESXi. По умолчанию этот параметр равен false, и сети VMotion для хартбитов не используются. Если установлен в значение true – VMware HA использует группу портов VMkernel с включенной опцией VMotion.
das.allowNetwork[n] – имя интерфейса сервисной консоли (например, ServiceConsole2), который будет использоваться для обмена хартбитами. n – номер, который отражает в каком порядке это будет происходить. Важно! - не ошибитесь, НЕ пишите das.allowNetworkS.
das.isolationShutdownTimeout - значение в секундах, которое используется как таймаут перед срабатыванием насильственного выключения виртуальной машины (power off), если не сработало мягкое выключение из гостевой ОС (shutdown). В случае выставления isolation response как shutdown, VMware HA пытается выключить ее таким образом в течение 300 секунд (значение по умолчанию). Обратите внимание, что значение в секундах, а не в миллисекундах.
das.ignoreRedundantNetWarning - значение-флаг (true или false, по умолчанию false), который при установке в значение false отключает нотификацию об отсутствии избыточности в сети управления («Host xxx currently has no management network redundancy»). По умолчанию установлено в значение false.
Настройки VM Monitoring для VMware HA платформы vSphere 5.0 и более ранних версий:
das.vmFailoverEnabled - значение-флаг (true или false). Если установлен в значение true – механизм VMFM включен, если false – выключен. По умолчанию установлено значение false.
das.FailureInterval - значение в секундах, после которого виртуальная машина считается зависшей и перезагружается, если в течение этого времени не получено хартбитов. По умолчанию установлено значение 30.
das.minUptime - значение в секундах, отражающее время, которое дается на загрузку виртуальной машины и инициализацию VMware Tools для обмена хартбитами. По умолчанию установлено значение 120.
das.maxFailures - максимальное число автоматических перезагрузок из-за неполучения хартбитов, допустимое за время, указанное в параметре das.maxFailureWindow. Если значение das.maxFailureWindow равно «-1», то das.maxFailures означает абсолютное число отказов или зависаний ОС, после которого автоматические перезагрузки виртуальной машины прекращаются, и отключается VMFM. По умолчанию равно 3.
das.maxFailureWindow - значение, отражающее время в секундах, в течение которого рассматривается значение параметра das.maxFailures. По умолчанию равно «-1». Например, установив значение 86400, мы получим, что за сутки (86400 секунд) может произойти 3 перезапуска виртуальной машины по инициативе VMFM. Если перезагрузок будет больше, VMFM отключится. Значение параметра das.maxFailureWindow может быть также равно «-1». В этом случае время рассмотрения числа отказов для отключения VMFM – не ограничено.
Настройки, которые больше не действуют в vSphere 5.0:
das.failuredetectiontime
Работает только в vSphere 4.1 и более ранних версиях (см. ниже).
Раньше была настройка das.failuredetectiontime - это значение в миллисекундах, которое отражает время, через которое VMware HA признает хост изолированным, если он не получает хартбитов (heartbeats) от других хостов и isolation address недоступен. После этого срабатывает действие isolation response, которое выставляется в параметрах кластера в целом, либо для конкретной виртуальной машины. По умолчанию, значение равно 15000 (15 секунд). Рекомендуется увеличить это время до 60000 (60 секунд), если с настройками по умолчанию возникают проблемы в работе VMware HA. Если у вас 2 интерфейса обмена хартбитами - можно оставить 15 секунд.
В VMware vSphere 5, в связи с тем, что алгоритм HA был полностью переписан, настройка das.failuredetectiontime для кластера больше не акутальна.
Теперь все работает следующим образом (см. также новые das-параметры, которые были описаны выше).
Наступление изоляции хост-сервера ESXi, не являющегося Master (т.е. Slave):
Время T0 – обнаружение изоляции хоста (slave).
T0+10 сек – Slave переходит в состояние "election state" (выбирает "сам себя").
T0+25 сек – Slave сам себя назначает мастером.
T0+25 сек – Slave пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+30 сек – Slave объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Наступление изоляции хост-сервера ESXi, являющегося Master:
T0 – обнаружение изоляции хоста (master).
T0 – Master пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+5 сек – Master объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Как мы видим, алгоритм для мастера несколько другой, чтобы при его изоляции остальные хосты ESXi смогли быстрее начать выборы и выбрать нового мастера. После падения мастера, новый выбранный мастер управляет операциями по восстановлению ВМ изолированного хоста. Если упал Slave - то, понятное дело, восстановлением его ВМ управляет старый мастер. И да, помним, что машины будут восстанавливаться, только если в Isolation Responce стоит Shutdown или Power Off, чтобы хост мог их погасить.
das.bypassNetCompatCheck
Работает только в vSphere 4.1 и более ранних версиях (см. ниже).
Это значение-флаг (true или false, по умолчанию false), который будучи установлен в значение true позволяет обойти дополнительную проверку на совместимость с HA. В VirtualCenter Update 2 была введена проверка на совместимость подсетей, по которым ходят хартбиты. Возникала ошибка: «HA agent on in cluster in has an error Incompatible HA Network: Consider using the Advanced Cluster Settings das.allowNetwork to control network usage». Теперь, если сети считаются несовместимыми с точки зрения HA, однако маршрутизируемыми – новая опция поможет осуществить корректную настройку кластера.
Таги: VMware, HA, FDM, VMachines, ESXi, Обучение, vSphere
Если вы обновляли хосты VMware vSphere 4.1 на vSphere 5.0, то у вас может возникнуть ошибка "Operation timed out" при переходе хост-сервера ESXi 5.0 в состояние "Election", т.е. выбора мастера операций (см. нашу статью о VMware HA в vSphere 5.0).
Когда инициируется запрос "start" для FDM, агент не запускается и HA пытается переустановить его, что также заканчивается неудачно, поскольку он имеет правильную версию и вроде как установлен нормально. Однако HA в этом случае не работает. Детали вы найдете вот в этой ветке на VMTN.
Это очередное доказательство той мысли, которую мы доносим с выходом каждой новой мажорной версии vSphere - никогда не делайте апгрейд на новую версию, а всегда переустанавливайте хост-серверы ESXi (потому что баги выползают буквально с каждым релизом).
Для решения проблемы нужно сделать следующее:
Перевести хост в режим обслуживания (Maintenance Mode) и убрать с него все ВМ.
Скопировать файл /opt/vmware/uninstallers/VMware-fdm-uninstall.sh куда-нибудь во временную папку (например, /tmp)
Из приведенной выше папки (/tmp) запустить скрипт ./VMware-fdm-uninstall.sh
Будет небольшая задержка на выполнение скрипта.
Вывести хост из Mainenance Mode и на панели "Recent Tasks" убедиться, что vCenter начал переустановку агента.
Это, по-идее, должно помочь. Ну и не забывайте, что все логи VMware HA на хосте (а именно, FDM-агента) хранятся в файле var/log/fdm.log.
Очень полезной может оказаться не только указанная ветка Community, но и статья KB 2004429.
Update: проблема оказывается серьезнее - она касается также ситуации, когда вы просто накатили патчи на ESXi 5.0 (см. комментарии).
Таги: VMware, HA, Bugs, Bug, vSphere, ESXi, Upgrade
Мы уже писали о решении EMC VPLEX, которое позволяет организовать катастрофоустойчивую архитектуру хранилищ для виртуальных машин за счет организации синхронного распределенного виртуального тома (Disrtibuted Virtual Volume).
Семейство продуктов EMC VPLEX с операционной системой EMC GeoSynchrony является решением по объединению на основе сети SAN. Технология EMC VPLEX Metro позволяет объединить дисковые ресурсы массивов, находящихся на двух географически разделенных площадках в единый пул хранения. Со стороны серверов ESX / ESXi на обеих площадках доступен один виртуальный логический том, который обладает свойством катастрофоустойчивости, поскольку данные физически хранятся и синхронизируются на обеих площадках.
Данная технология интегрирована с технологией отказоустойчивости VMware HA за счет поддержки структуры vSphere Metro Storage Cluster, что позволяет использовать их совместно для обработки различных вариантов сбоев в виртуальной инфраструктуре. К тому же, EMC VPLEX - это единственное сертифицированное VMware решение для организации географически "растянутых" кластеров VMware HA.
В географически разнесенных ЦОД, хранилища которых синхронизированы с помощью VPLEX, есть важная проблема – является ли нарушение связи между узлами кластеров VPLEX следствием сбоя сети или сбоя на площадке. Она затрагивает и кластеры VPLEX, которые находятся в различных географических точках. Система EMC VPLEX обрабатывает сбой сети путем автоматического прекращения всех операций ввода-вывода в устройстве («отключение») на одной из двух площадок в зависимости от набора преопределенных правил. Операции ввода-вывода в то же устройство на другой площадке продолжают выполняться в обычном режиме. Поскольку правила применяются к каждому устройству в отдельности, в случае разделения сети активные устройства могут присутствовать на обеих площадках. Для предотвращения этого используется Cluster Witness - компонент на сторонней площадке, отвечающий за мониторинг доступности основной и резервной площадки.
При отказе различных компонентов ИТ-инфраструктуры и каналов связи могут возникнуть различные ситуации как для кластера VPLEX, так и для кластера VMware HA, которые успешно обрабатываются и теоретически весьма мало ситуаций, которые могут привести к потере данных. Однако есть ситуации (и они всегда будут в распределенных ЦОД - именно потому RTO=0 это Objective, а не Requirement), когда нельзя автоматизировать операции по восстановлению и требуется вмешательство администратора, который выполнит наиболее правильное действие.
Вот как VPLEX совместно с HA обрабатывают различные варианты сбоев:
Сценарий
Поведение VPLEX
Влияние на кластер VMware HA
Отказ одного из путей порта
VPLEX back-end
(BE) к дисковому массиву.
VPLEX прозрачно переключится на альтернативный путь, без влияния на работу распределенных виртуальных томов (Distributed Virtual Volumes).
Отсутствует.
Отказ одного из путей к порту VPLEX front-end
(FE) от хост-сервера.
Сервер ESXi за счет встроенного механизма работы по нескольким путям переключится на резервный путь к распределенным виртуальным томам.
Отсутствует.
Выход из строя массива
на основной площадке.
VPLEX продолжит обслуживать виртуальные тома, используя дисковый массив резервной площадки. Когда основной дисковый массив восстановится после сбоя, тома основного дискового массива будут автоматически синхронизированы с резервного.
Отсутствует.
Выход из строя массива на резервной площадке.
VPLEX продолжит обслуживать виртуальные тома, используя дисковый массив основной площадки. Когда резервный дисковый массив восстановится после сбоя, тома резервного дискового массива будут автоматически синхронизированы с основного.
Отсутствует.
Выход из строя одного из устройств VPLEX Director.
VPLEX продолжит обслуживать виртуальные тома, перенаправив запросы на другие директоры кластера VPLEX.
Отсутствует.
Полная потеря основной площадки (катастрофа), включая все хосты ESXi и компоненты кластера VPLEX (обнаруживается с помощью Cluster Witness).
VPLEX продолжит обслуживать запросы ввода-вывода на дисковом массиве резервной площадки. Когда основная площадка восстановится, виртуальные тома будут синхронизированы с резервной площадки.
Виртуальные машины основной площадки будут перезапущены на хостах резервной площадки.
Полная потеря резервной площадки (катастрофа), включая все хосты ESXi и компоненты кластера VPLEX (обнаруживается с помощью Cluster Witness).
VPLEX продолжит обслуживать запросы ввода-вывода на дисковом массиве основной площадки. Когда резервная площадка восстановится, виртуальные тома будут синхронизированы с основной площадки.
Виртуальные машины резервной площадки будут перезапущены на хостах основной площадки.
Множественный выход из строя хост-серверов в рамках одной из площадок.
Отсутствует
Механизм VMware HA перезапустит виртуальные машины на оставшихся хостах кластера HA.
Выход из строя сети сигналов доступности в рамках одной из площадок.
Отсутствует.
HA продолжит обмен сигналами доступности через общие хранилища (см. тут), что не повлечет за собой аварийного восстановления.
Все пути к хосту ESXi находятся в состоянии APD (All Paths down) – т.е. временно отсутствует доступ к хранилищам (виртуальным томам).
Отсутствует.
В этом случае необходимо перезапустить сервер ESXi, что приведет к перезапуску виртуальных машин в кластере HA на других хост-серверах кластера HA.
Разрыв канала репликации между устройствами VPLEX при сохранении сети управления.
На резервной площадке VPLEX переводит виртуальные тома в режим I/O Failure (что запрещает работу с ними). На основной площадке виртуальные тома продолжают оставаться доступными виртуальным машинам.
На основной площадке виртуальные машины продолжают функционировать. На резервной площадке виртуальные машины получают ошибку ввода-вывода и выключаются. Механизм VMware HA (VM Monitoring) восстанавливает их на резервной площадке.
Сбой кластера VPLEX (компоненты кластера на обеих площадках недоступны, но хосты ESXi не испытывают проблем работы по SAN и СПД).
Запросы ввода-вывода для всех виртуальных томов продолжат обслуживаться на основной площадке.
Хосты ESXi на резервной площадке перейдут в состояние APD. Это потребует их перезагрузки для восстановления виртуальных машин.
Одновременный полный выход из строя обеих площадок.
После восстановления площадок VPLEX продолжит обслуживать запросы ввода-вывода (в первую очередь следует запустить дисковые массивы на обеих площадках).
Хосты ESXi должны быть включены только после того, как компоненты VPLEX будут восстановлены, а виртуальные тома синхронизированы. При включении хостов ESXi виртуальные машины будут восстановлены механизмом VMware HA.
Выход из строя одного из директоров VPLEX на одной из площадок, а также выход дискового массива на противоположной площадке (резервная площадка для виртуального тома).
Оставшиеся директоры кластера VPLEX продолжат обслуживать доступ к виртуальным томам, используя дисковый массив, являющийся для них основным.
Отсутствует
Разрыв сети сигналов доступности (heartbeat) на одной из площадок и разрыв коммуникаций VPLEX между площадками (отличие от выхода из строя площадки понимает Cluster Witness).
VPLEX прекращает обслуживать запросы ввода-вывода для виртуальных томов, у которых дисковые массивы помечены как резервные. Обмен продолжится только с дисковыми массивами, являющимися основными для виртуальных томов.
На основной площадке виртуальные машины продолжат исполняться. Для VMware HA – это ситуация «split-brain» (хосты резервной площадки считают себя оставшимися работоспособными в кластере и пытаются включить виртуальные машины). При включении ВМ на хостах резервной площадки будет получена ошибка ввода-вывода. В этой ситуации необходимо вручную перерегистрировать виртуальные машины резервной площадки на основной.
Том VPLEX оказывается недоступен (например, случайно удален из консоли управления).
VPLEX продолжит обслуживать запросы ввода-вывода с резервной площадки, где том доступен.
Все хосты ESXi работающие с томом VPLEX получают ошибку ввода-вывода и переходят в состояние PDL (Permanent Device Loss). В результате компонент VM Monitoring останавливает виртуальные машины, после чего они запускаются на хостах другой площадки.
Разрыв соединения между компонентами VPLEX на обеих площадках и одновременных выход из строя соединения VPLEX Cluster Witness к основной площадке.
VPLEX прекращает обслуживать запросы ввода-вывода к виртуальным томам на резервной площадке и продолжает работу с томами основной площадки.
Виртуальные машины на резервной площадке завершат работу по ошибке ввода-вывода, они могут быть вручную зарегистрированы и запущены на резервной площадке.
Разрыв соединения между компонентами VPLEX на обеих площадках и одновременных выход из строя соединения VPLEX Cluster Witness к основной площадке.
VPLEX прекращает обслуживать запросы ввода-вывода к виртуальным томам на основной площадке и продолжает работу с томами резервной площадки.
Виртуальные машины на основной площадке завершат работу по ошибке ввода-вывода, они могут быть вручную зарегистрированы и запущены на резервной площадке.
Сбой компонента VPLEX Cluster Witness.
VPLEX продолжает обслуживать запросы ввода-вывода на обеих площадках.
Отсутствует.
Сбой компонента VPLEX Management Server на одной из площадок.
Отсутствует.
Отсутствует.
Отказ сервера управления виртуальной инфраструктурой VMware vCenter
Отсутствует.
На механизм VMware HA и восстановления виртуальных машин это не повлияет. Однако правила размещения и балансировки виртуальных машин по хост-серверам прекратят работать.
Как видите, все ситуации обрабатываются разумно и корректно. Тут обязательным должно быть наличие VPLEX Cluster Witness, который отличит выход из строя линков между ЦОД от выхода из строя одного из ЦОД, о чем он скажет им обоим.
Также надо отметить, что полной автоматизации восстановления тут нельзя добиться, как говорится, "by design".
Многие пользователи VMware vSphere знают, что для кластера HA раньше была настройка das.failuredetectiontime - значение в миллисекундах, которое отражает время, через которое VMware HA признает хост изолированным, если он не получает хартбитов (heartbeats) от других хостов и isolation address недоступен. После этого времени срабатывает действие isolation response, которое выставляется в параметрах кластера в целом, либо для конкретной виртуальной машины.
В VMware vSphere 5, в связи с тем, что алгоритм HA был полностью переписан, настройка das.failuredetectiontime для кластера больше не акутальна.
Теперь все работает следующим образом.
Наступление изоляции хост-сервера ESXi, не являющегося Master (т.е. Slave):
Время T0 – обнаружение изоляции хоста (slave).
T0+10 сек – Slave переходит в состояние "election state" (выбирает "сам себя").
T0+25 сек – Slave сам себя назначает мастером.
T0+25 сек – Slave пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+30 сек – Slave объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Наступление изоляции хост-сервера ESXi, являющегося Master:
T0 – обнаружение изоляции хоста (master).
T0 – Master пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+5 сек – Master объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Как мы видим, алгоритм для мастера несколько другой, чтобы при его изоляции остальные хосты ESXi смогли быстрее начать выборы и выбрать нового мастера. После падения мастера, новый выбранный мастер управляет операциями по восстановлению ВМ изолированного хоста. Если упал Slave - то, понятное дело, восстановлением его ВМ управляет старый мастер. Помним, да, что машины будут восстанавливаться, только если в Isolation Responce стоит Shutdown или Power Off, чтобы хост мог их погасить.
Интересный момент обнаружился на блогах компании VMware. Оказывается, если вы используете в кластере VMware HA разные версии платформы VMware ESXi (например, 4.1 и 5.0), то при включенной технологии Storage DRS (выравнивание нагрузки на хранилища), вы можете повредить виртуальный диск вашей ВМ, что приведет к его полной утере.
In clusters where Storage vMotion is used extensively or where Storage DRS is enabled, VMware recommends that you do not deploy vSphere HA. vSphere HA might respond to a host failure by restarting a virtual machine on a host with an ESXi version different from the one on which the virtual machine was running before the failure. A problem can occur if, at the time of failure, the virtual machine was involved in a Storage vMotion action on an ESXi 5.0 host, and vSphere HA restarts the virtual machine on a host with a version prior to ESXi 5.0. While the virtual machine might power on, any subsequent attempts at snapshot operations could corrupt the vdisk state and leave the virtual machine unusable.
По русски это выглядит так:
Если вы широко используете Storage vMotion или у вас включен Storage DRS, то лучше не использовать кластер VMware HA. Так как при падении хост-сервера ESXi, HA может перезапустить его виртуальные машины на хостах ESXi с другой версией (а точнее, с версией ниже 5.0, например, 4.1). А в это время хост ESXi 5.0 начнет Storage vMotion, соответственно, во время накатывания последовательности различий vmdk (см. как работает Storage vMotion) машина возьмет и запустится - и это приведет к порче диска vmdk.
Надо отметить, что такая ситуация, когда у вас в кластере используется только ESXi 5.0 и выше - произойти не может. Для таких ситуаций HA и Storage vMotion полностью совместимы.
Многие задаются вопросом - а как себя поведет кластер VMware HA в vSphere 5 при отключении всех хост-серверов VMware ESXi 5 (например, отключение электричества в датацентре)?
Алгоритм в этом случае таков:
1. Все хосты выключаются, виртуальные машины на них помечаются как выключенные некорректно.
2. Вы включаете все хосты при появлении питания.
3. Между хостами ESXi происходят выборы Master (см. статью про HA).
4. Master читает список защищенных HA виртуальных машин.
5. Master инициирует запуск виртуальных машин на хостах-членах кластера HA.
Надо отметить, что восстановлении VMware HA смотрит на то, какие из них были выключены некорректно (в случае аварии), и для таких ВМ инициирует их запуск. Виртуальные машины выключенные корректно (например, со стороны администратора) запущены в этом случае не будут, как и положено.
Отличия от четвертой версии vSphere здесь в том, что вам не надо первыми включать Primary-узлы HA (для ускорения восстановления), поскольку в vSphere 5 таких узлов больше нет. Теперь просто можете включать серверы в произвольном порядке.
Скоро нам придется участвовать в интереснейшем проекте - построение "растянутого" кластера VMware vSphere 5 на базе технологии и оборудования EMC VPLEX Metro с поддержкой возможностей VMware HA и vMotion для отказоустойчивости и распределения нагрузки между географически распределенными ЦОД.
Вообще говоря, решение EMC VPLEX весьма новое и анонсировано было только в прошлом году, но сейчас для нашего заказчика уже едут модули VPLEX Metro и мы будем строить active-active конфигурацию ЦОД (расстояние небольшое - где-то 3-5 км) для виртуальных машин.
Для начала EMC VPLEX - это решение для виртуализации сети хранения данных SAN, которое позволяет объединить ресурсы различных дисковых массивов различных производителей в единый логический пул на уровне датацентра. Это позволяет гибко подходить к распределению дискового пространства и осуществлять централизованный мониторинг и контроль дисковых ресурсов. Эта технология называется EMC VPLEX Local:
С физической точки зрения EMC VPLEX Local представляет собой набор VPLEX-директоров (кластер), работающих в режиме отказоустойчивости и балансировки нагрузки, которые представляют собой промежуточный слой между SAN предприятия и дисковыми массивами в рамках одного ЦОД:
В этом подходе есть очень много преимуществ (например, mirroring томов двух массивов на случай отказа одного из них), но мы на них останавливаться не будем, поскольку нам гораздо более интересна технология EMC VPLEX Metro, которая позволяет объединить дисковые ресурсы двух географически разделенных площадок в единый пул хранения (обоим площадкам виден один логический том), который обладает свойством катастрофоустойчивости (и внутри него на уровне HA - отказоустойчивости), поскольку данные физически хранятся и синхронизируются на обоих площадках. В плане VMware vSphere это выглядит так:
То есть для хост-серверов VMware ESXi, расположенных на двух площадках есть одно виртуальное хранилище (Datastore), т.е. тот самый Virtualized LUN, на котором они видят виртуальные машины, исполняющиеся на разных площадках (т.е. режим active-active - разные сервисы на разных площадках но на одном хранилище). Хосты ESXi видят VPLEX-директоры как таргеты, а сами VPLEX-директоры являются инициаторами по отношению к дисковым массивам.
Все это обеспечивается технологией EMC AccessAnywhere, которая позволяет работать хостам в режиме read/write на массивы обоих узлов, тома которых входят в общий пул виртуальных LUN.
Надо сказать, что технология EMC VPLEX Metro поддерживается на расстояниях между ЦОД в диапазоне до 100-150 км (и несколько более), где возникают задержки (latency) до 5 мс (это связано с тем, что RTT-время пакета в канале нужно умножить на два для FC-кадра, именно два пакета необходимо, чтобы донести операцию записи). Но и 150 км - это вовсе немало.
До появления VMware vSphere 5 существовали некоторые варианты конфигураций для инфраструктуры виртуализации с использованием общих томов обоих площадок (с поддержкой vMotion), но растянутые HA-кластеры не поддерживались.
С выходом vSphere 5 появилась технология vSphere Metro Storage Cluster (vMSC), поддерживаемая на сегодняшний день только для решения EMC VPLEX, но поддерживаемая полностью согласно HCL в плане технологий HA и vMotion:
Обратите внимание на компонент посередине - это виртуальная машина VPLEX Witness, которая представляет собой "свидетеля", наблюдающего за обоими площадками (сам он расположен на третьей площадке - то есть ни на одном из двух ЦОД, чтобы его не затронула авария ни на одном из ЦОД), который может отличить падения линка по сети SAN и LAN между ЦОД (экскаватор разрезал провода) от падения одного из ЦОД (например, попадание ракеты) за счет мониторинга площадок по IP-соединению. В зависимости от этих обстоятельств персонал организации может предпринять те или иные действия, либо они могут быть выполнены автоматически по определенным правилам.
Теперь если у нас выходит из строя основной сайт A, то механизм VMware HA перезагружает его ВМ на сайте B, обслуживая их ввод-вывод уже с этой площадки, где находится выжившая копия виртуального хранилища. То же самое у нас происходит и при массовом отказе хост-серверов ESXi на основной площадке (например, дематериализация блейд-корзины) - виртуальные машины перезапускаются на хостах растянутого кластера сайта B.
Абсолютно аналогична и ситуация с отказами на стороне сайта B, где тоже есть активные нагрузки - его машины передут на сайт A. Когда сайт восстановится (в обоих случаях с отказом и для A, и для B) - виртуальный том будет синхронизирован на обоих площадках (т.е. Failback полностью поддерживается). Все остальные возможные ситуации отказов рассмотрены тут.
Если откажет только сеть управления для хостов ESXi на одной площадке - то умный VMware HA оставит её виртуальные машины запущенными, поскольку есть механизм для обмена хартбитами через Datastore (см. тут).
Что касается VMware vMotion, DRS и Storage vMotion - они также поддерживаются при использовании решения EMC VPLEX Metro. Это позволяет переносить нагрузки виртуальных машин (как вычислительную, так и хранилище - vmdk-диски) между ЦОД без простоя сервисов. Это открывает возможности не только для катастрофоустойчивости, но и для таких стратегий, как follow the sun и follow the moon (но 100 км для них мало, специально для них сделана технология EMC VPLEX Geo - там уже 2000 км и 50 мс latency).
Самое интересное, что скоро приедет этот самый VPLEX на обе площадки (где уже есть DWDM-канал и единый SAN) - поэтому мы все будем реально настраивать, что, безусловно, круто. Так что ждите чего-нибудь про это дело интересного.
Таги: VMware, HA, Metro, EMC, Storage, vMotion, DRS, VPLEX
Одно из существенных изменений, Datastore Heartbeating - механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами. Напомним, что в качестве heartbeat-хранилищ выбираются два, и они могут быть определены пользователем. Выбираются они так: во-первых, они должны быть на разных массивах, а, во-вторых, они должны быть подключены ко всем хостам.
Если у вас доступно общее хранилище только одно, вы получите такое предупреждение в vSphere Client:
Теперь еще один момент, на который хочется обратить внимание. Помните, что в настройках VMware HA есть варианты выбора действия для хост-сервера по отношении к своим виртуальным машинам в том случае, когда он обнаруживает, что изолирован от сети (параметр Isolation Responce):
Напомним, что Isolation Responce может принимать следующие значения:
Leave powered on (по умолчанию в vSphere 5 - оптимально для большинства сценариев)
Power off
Shutdown
Выбирать правильную настройку нужно следующим образом:
Если наиболее вероятно что хост ESXi отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Разницу между Power off и Shutdown многие из вас знают - во втором случае машина выключается средствами гостевой системы, а в первом случае - это жесткое выключение средствами хост-сервера. Казалось бы, лучше всего ставить второй вариант (Shutdown). Но это не всегда так. Дело в том, что при действии shutdown у гостевой ОС может не получиться погасить систему (например, вылетит exception или еще что). В этом случае хост ESXi будет пытаться сделать shutdown в течение 5 минут до того, как он уже сделает действие power off.
Это приведет к тому, что время восстановления работоспособности сервиса вполне может увеличиться на 5 минут, что может быть критично для некоторых задач (с высокими требованиями к RTO). Зато в случае shutdown у вас произойдет корректное завершение работы сервера, а при power off могут не сохраниться данные, нарушиться консистентность и т.п. Выбирайте.
В первой части статьи мы уже рассматривали наиболее оптимальную конфигурацию средства VMware vSphere Storage Appliance для создания отказоустойчивого кластера хранилищ из трех хостов и описали, что происходит с хранилищами при отказе сети синхронизации (Back-End Network). Во второй части статьи мы расскажем о том, как конфигурация VSA отрабатывает отказ сети управления и экспорта NFS-хранилищ (Front-End).
Мы уже писали о новом продукте VMware vSphere Storage Appliance (VSA), который позволяет создать кластер хранилищ на базе трех серверов (3 хоста ESXi 5 или 2 хоста ESXi 5 + физ. хост vCenter), а также о его некоторых особенностях. Сегодня мы рассмотрим, как работает кластер VMware VSA, и как он реагирует на пропадание сети на хосте (например, поломка адаптеров) для сети синхронизации VSA (то есть та, где идет зеркалирование виртуальных хранилищ).
Таги: VMware, VSA, vSphere, Обучение, ESXi, Storage, HA, Network
Мы уже много писали о различных технических аспектах новой версии серверной платформы виртуализации VMware vSphere 5 и особенностях лицензирования, но в этой статье постараемся сделать суммарный обзор функциональности различных изданий продукта, краткое описание состава пакетов ПО (Acceleration Kits и Essentials), а также детально рассмотреть особенности лицензирования.
Вы уже читали, что в VMware vSphere 5 механизм отказоустойчивости виртуальных машин VMware High Availability претерпел значительные изменения. Точнее, он не просто изменился - его полностью переписали с нуля. То есть переделали совсем, изменив логику работы, принцип действия и убрав многие из существующих ограничений. Давайте взглянем поподробнее, как теперь работает новый VMware HA с агентами Fault Domain Manager...
Таги: VMware, vSphere, HA, Update, ESXi, Storage, vCenter, FDM
Вместе с релизом продуктовой линейки VMware vSphere 5, VMware SRM 5 и VMware vShield 5 компания VMware объявила о выходе еще одного продукта - VMware vSphere Storage Appliance. Основное назначение данного продукта - дать пользователям vSphere возможность создать общее хранилище для виртуальных машин, для которого будут доступны распределенные сервисы виртуализации: VMware HA, vMotion, DRS и другие.
Для некоторых малых и средних компаний виртуализация серверов подразумевает необходимость использовать общие хранилища, которые стоят дорого. VMware vSphere Storage Appliance предоставляет возможности общего хранилища, с помощью которых малые и средние компании могут воспользоваться средствами обеспечения высокой доступности и автоматизации vSphere. VSA помогает решить эти задачи без дополнительного сетевого оборудования для хранения данных.
Кстати, одна из основных идей продукта - это подвигнуть пользователей на переход с vSphere Essentials на vSphere Essentials Plus за счет создания дополнительных выгод с помощью VSA для распределенных служб HA и vMotion.
Давайте рассмотрим возможности и архитектуру VMware vSphere Storage Appliance:
Как мы видим, со стороны хостов VMware ESXi 5, VSA - это виртуальный модуль (Virtual Appliance) на базе SUSE Linux, который представляет собой служебную виртуальную машину, предоставляющую ресурсы хранения для других ВМ.
Чтобы создать кластер из этих виртуальных модулей нужно 2 или 3 хоста ESXi 5. Со стороны сервера VMware vCenter есть надстройка VSA Manager (отдельная вкладка в vSphere Client), с помощью которой и происходит управление хранилищами VSA.
Каждый виртуальный модуль VSA использует пространство на локальных дисках серверов ESXi, использует технологию репликации в целях отказоустойчивости (потому это и кластер хранилищ) и позволяет эти хранилища предоставлять виртуальным машинам в виде ресурсов NFS.
Как уже было сказано, VMware VSA можно развернуть в двух конфигурациях:
2 хоста ESXi - два виртуальных модуля на каждом хосте и служба VSA Cluster Service на сервере vCenter.
3 хоста ESXi - на каждом по виртуальному модулю (3-узловому кластеру служба на vCenter не нужна)
С точки зрения развертывания VMware VSA - очень прост, с защитой "от дурака" и не требует каких-либо специальных знаний в области SAN (но во время установки модуля на хосте ESXi не должно быть запущенных ВМ)...
Компания VMware в июле 2011 года объявила о доступности новых версий целой линейки своих продуктов для облачных вычислений, среди которых находится самая технологически зрелая на сегодняшний день платформа виртуализации VMware vSphere 5.0.
Мы уже рассказывали об основном наборе новых возможностей VMware vSphere 5.0 неофициально, но сейчас ограничения на распространение информации сняты, и мы можем вполне официально рассказать о том, что нового для пользователей дает vSphere 5.

 RSS
RSS